Optimize Vector Database Storage: Quantization & MRL Explained
Vector databases are the backbone of modern AI systems, enabling features like Retrieval-Augmented Generation (RAG) and long-term memory. However, as datasets grow, storage costs for vector indexes can skyrocket—often reaching $6,000/month for 100 million vectors. For engineering teams, this is where optimization becomes critical. In this article, we’ll explore two proven techniques—quantization and Matryoshka Representation Learning (MRL)—to reduce infrastructure costs while maintaining retrieval accuracy.
The Cost Challenge in Vector Databases
Vector storage costs stem from two factors: precision and dimensionality. A standard 1024-dimensional embedding uses 4 KB per vector (1024 x 4 bytes). With replication for high availability, this jumps to 12 KB per vector. At scale, 100 million vectors require 1.2 TB of RAM—plus additional overhead for index structures like HNSW.
Cloud storage pricing at $5/GB/month means infrastructure costs quickly become a bottleneck. This is where optimization techniques like quantization and MRL shine.
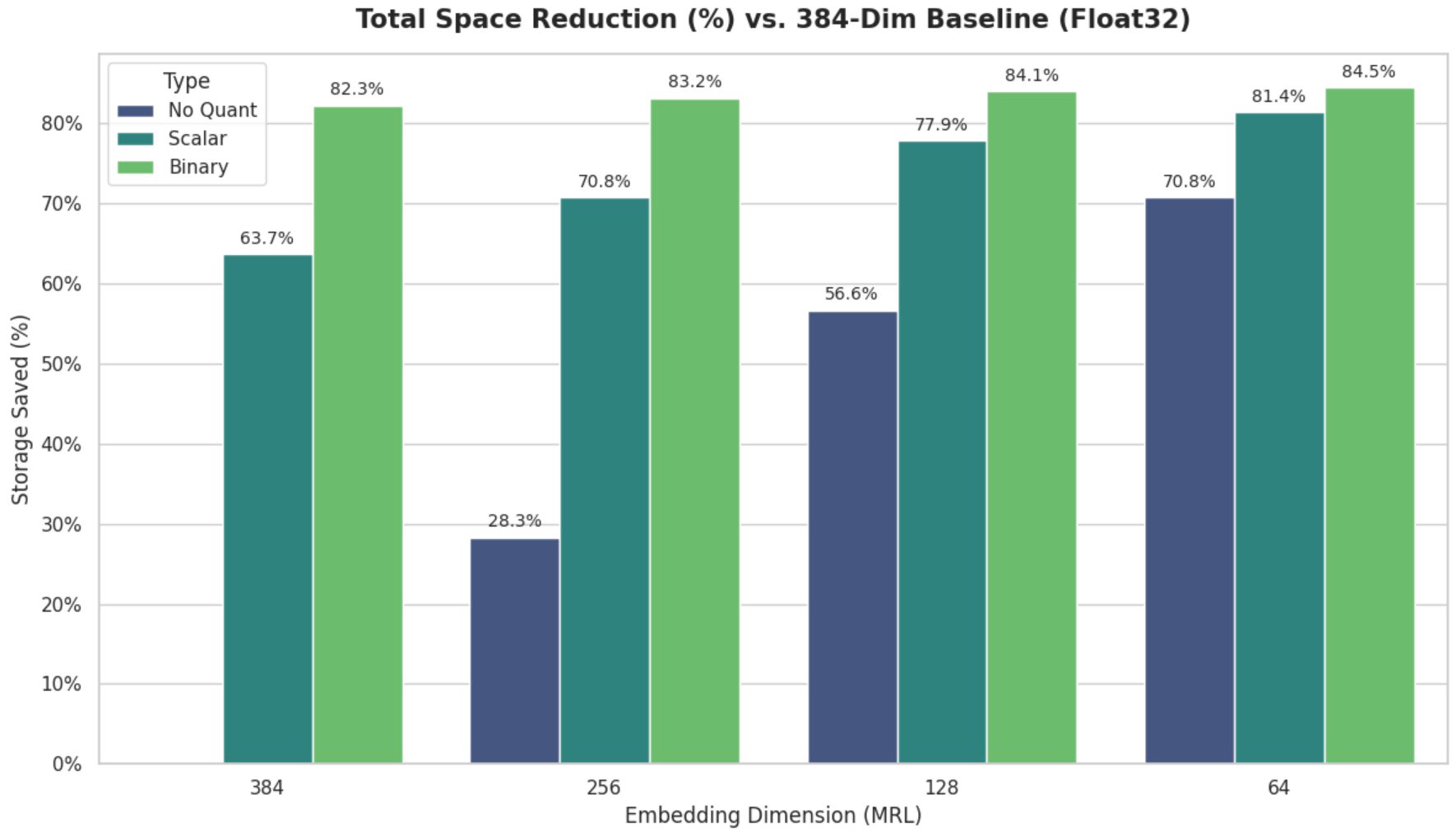
Quantization: Precision Reduction for Storage Savings
Quantization reduces the precision of vector elements, shrinking storage requirements. Three common methods include:
- Scalar Quantization: Converts 32-bit floats to 8-bit integers (4x storage reduction, minimal accuracy loss).
- Binary Quantization: Reduces to 1-bit (32x reduction, but risks significant accuracy drops).
- Product Quantization: Clusters vector chunks for compression, though it adds computational overhead.
Scalar quantization is the sweet spot for most production systems, balancing cost and performance.
Matryoshka Representation Learning (MRL): Dimensionality Compression
MRL tackles storage from a different angle: reducing vector dimensionality. By training models to prioritize semantic information in early dimensions, engineers can truncate vectors from 1024 to 64 dimensions with minimal accuracy loss. For example:
- 1024 → 256 dimensions: 4x storage reduction.
- 1024 → 64 dimensions: 16x reduction.
This technique works best with models like mxbai-embed-xsmall-v1, which natively support MRL. Combined with quantization, it can achieve up to 64x compression.
Empirical Results: Quantization vs. MRL
We tested these methods using FAISS and the mteb/hotpotQA dataset. Key findings include:
- Scalar Quantization reduced storage by 4x with <1% accuracy drop.
- MRL (128 dimensions) cut storage by 8x while retaining 95% accuracy.
- Combined methods achieved 32x compression with <3% accuracy loss.
These results highlight the trade-off between cost and performance. For most applications, scalar quantization + MRL offers the best balance.
When to Use Each Technique
Choose based on your use case:
- Quantization: Ideal for latency-sensitive applications (e.g., real-time search).
- MRL: Best for cost-sensitive workloads (e.g., archival datasets).
- Combined: Optimal for large-scale production systems.
For example, a recommendation engine might use scalar quantization to speed up queries, while a document archive could leverage MRL for long-term storage efficiency.
Conclusion: Reduce Costs Without Sacrificing Quality
Vector database storage optimization is no longer optional—it’s essential for scaling AI infrastructure. By combining quantization and MRL, teams can slash costs by 32x or more while maintaining high retrieval accuracy. Start with scalar quantization for immediate savings, then experiment with MRL to push compression further.
Ready to test these techniques? Check out our GitHub repository for reproducible code and benchmarks. Let’s build smarter, more cost-effective AI systems together.








