Pinterest’s CDC-Powered Ingestion Cuts Latency to 15 Minutes
Legacy database systems often struggle with high latency, operational complexity, and wasted resources. Pinterest faced these challenges head-on by redesigning its data ingestion framework using Change Data Capture (CDC) technology. The result? A dramatic reduction in data latency from 24 hours to just 15 minutes, enabling real-time analytics and machine learning workflows.
Why Legacy Systems Failed Pinterest
Before the overhaul, Pinterest relied on batch-based pipelines that reprocessed entire tables daily—even when less than 5% of records changed. This approach wasted compute and storage resources while delaying critical workflows. Key issues included:
- High latency: Analytics and ML teams waited over 24 hours for updated data.
- Operational fragmentation: Multiple pipelines led to inconsistent data quality and maintenance overhead.
- Limited deletion support: Row-level deletions weren’t natively handled, complicating data governance.
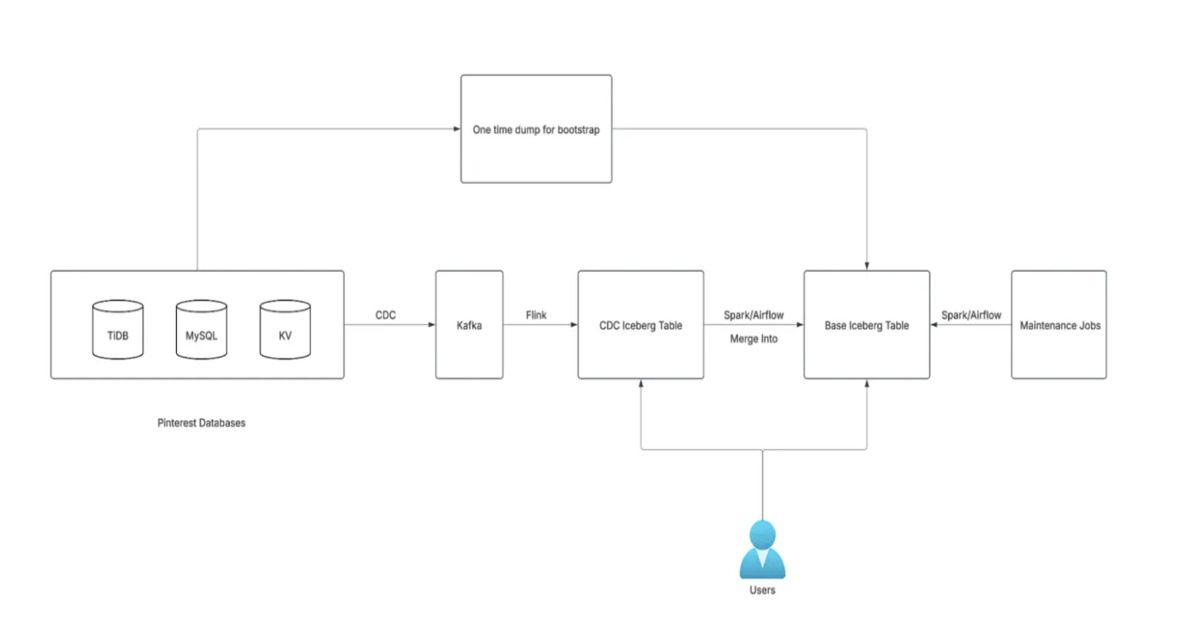
How CDC Transformed Pinterest’s Data Pipeline
Pinterest’s new framework leverages CDC tools like Debezium and TiCDC to capture real-time database changes. By processing only updated records, the system reduces resource usage and latency. Key components include:
- Kafka: Streams change events for low-latency processing.
- Flink and Spark: Handle streaming and batch workloads for scalable data processing.
- Iceberg: Manages base tables with efficient Merge on Read (MOR) strategy for cost-effective updates.
Architecture Highlights
The framework separates CDC tables (append-only ledgers of changes) from base tables (historical snapshots). Spark jobs deduplicate changes and apply updates every 15 minutes to an hour. Iceberg’s MOR strategy minimizes storage costs by avoiding full-file rewrites during updates.
Optimizations That Deliver Results
Pinterest’s approach prioritizes scalability and efficiency:
- Partitioning: Base tables are hashed by primary key, enabling parallel Spark upserts.
- Small file mitigation: Spark distributes writes by partition to avoid performance bottlenecks.
- Cost control: MOR reduces storage overhead compared to Copy on Write (COW) strategies.
Measurable Outcomes
The new system processes only 5% of daily records, slashing infrastructure costs. Key metrics include:
- Latency: From 24+ hours to 15 minutes for critical workflows.
- Scalability: Handles petabyte-scale data across thousands of pipelines.
- Cost savings: Eliminates redundant full-table operations.
Future Improvements
Pinterest plans to automate schema evolution, ensuring downstream pipelines adapt seamlessly to upstream changes. This will further enhance reliability and reduce manual maintenance.
Conclusion
Pinterest’s CDC-powered ingestion framework demonstrates how modern data architectures can balance speed, cost, and scalability. By adopting CDC and Iceberg’s MOR strategy, organizations can achieve real-time data availability without sacrificing efficiency.
Call to Action
Ready to optimize your data pipeline? Explore CDC tools and Iceberg’s Merge on Read strategy to reduce latency and costs in your workflows.








